Re: [問題] 用迴圈整理同個ID的看病次數
※ 引述《piggood (成為有品味的男人)》之銘言:
: ※ 引述《ntpuisbest (阿龍)》之銘言:
: : library(COUNT)
: : data(rwm5yr)
: : medical<-rwm5yr
: : https://imgur.com/xLr3I5j

: : 我的目的是像這樣
: : 同個id是同個人
: : 我想要把資料整理成
: : 去計算同個人的 總共 的看病次數
: : 其他的column 就用 同個id最後的 資訊
: : 最後要整理成
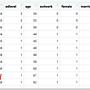
: : id docvis age
: : 1 1 56
: : 2 4 48
: : 3 13 62
: : 請問有套件可以做到這件事情嗎
: : 還是怎麼寫這個迴圈呢
: 目前想到的方式
: 但也不是很簡潔
: 不過還能用
: # 先建立一個 medical1 ,除了 docvis 和 hhninc 之外,都取最後一筆觀察值的資料
: medical1 <- medical %>%
: group_by(id) %>%
: summarise_at(vars(-docvis,-hhninc), last)
: # 再建 medical2 專門處理 docvis 跟 hhninc 的各別需求
: medical2 <- medical %>%
: group_by(id) %>%
: summarise(sum(docvis), mean(hhninc))
: # 合併在一起
: medical3 <- data.frame(medical2,medical1)
我都比較建議用data.table的方式,簡潔又快。
library(data.table)
setDT(medical)
medical <- medical[,docvis.sum:=sum(docvis), by = "id"][,hhninc.mean:=mean(hhninc), by =
"id"][, .SD[.N], by = "id"]
上面是data.table特殊chaining方式,若要考慮易讀性可以分3行。
medical[,docvis.sum:=sum(docvis), by = "id"]
medical[,hhninc.mean:=mean(hhninc), by = "id"]
medical <- medical[, .SD[.N], by = "id"]
或是pipe的方式。
medical <- medical[,docvis.sum:=sum(docvis), by = "id"] %>%
.[,hhninc.mean:=mean(hhninc), by = "id"] %>%
.[, .SD[.N], by = "id"]
--
※ 發信站: 批踢踢實業坊(ptt.cc), 來自: 101.10.51.71
※ 文章網址: https://www.ptt.cc/bbs/R_Language/M.1528794162.A.83A.html
推
06/12 18:42,
8年前
, 1F
06/12 18:42, 1F
→
06/12 18:46,
8年前
, 2F
06/12 18:46, 2F
→
06/12 18:48,
8年前
, 3F
06/12 18:48, 3F
→
06/12 18:49,
8年前
, 4F
06/12 18:49, 4F
→
06/12 18:50,
8年前
, 5F
06/12 18:50, 5F
推
06/20 17:01,
8年前
, 6F
06/20 17:01, 6F
討論串 (同標題文章)
R_Language 近期熱門文章

PTT數位生活區 即時熱門文章
