Re: [問題] 如何用Windows版的Python在cmd中印出檔 …
: 其實用 chcp 就可以改了
: 也可以改成 UTF-8, code page 碼是 65001
: 不過這樣不夠, 因為 Python 不認得 cp65001 是哪來的編碼
: 詳細可以看這個網頁的內容(Stack Overflow 的討論)http://goo.gl/qd4nY
稍微試了一下 結果是失敗的 還在查原因
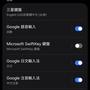
然而先不論結果 使用 chcp 65001 這方法有有幾個問題:
1. 無法使用輸入法
原因是 Windows 會根據 cmd 當前 code page 對應的 locale 來調用輸入法
例如 cp950 => zh_TW => 新注音, 新倉頡, ...
而 cp65001 => 沒有對應的locale => 沒有輸入法...
這樣當碰上需要 user input 時就只能複製貼上了
2. 字寬問題
像是CJKW這種double-width的字元在code page為65001時幾乎無法正確顯示
稍微動個cursor就會破壞顯示結果 http://i.imgur.com/W80lj.jpg

(給有心嘗試的人 chcp 65001後要把字型改成Lucida或Consolas才能顯示Unicode字元)
(一開始字型選項沒有Consolas 要去改登錄檔才有 改法請參考這網站
http://blog.wolffmyren.com/2008/09/15/consolas-as-cmdexe-windows-console-font/ )
另外還有一些小問題
例如每次進入cmd就得手動輸入chcp 65001等
(不過可以靠修改登錄檔解決:
http://superuser.com/questions/269818/change-default-code-page-of-windows-console-to-utf-8
但請注意不要改OEMCP
否則下次開機會跟我一樣進不了Windows(還好我是用VM測的) )
總之不太建議用這方法
: 上面講了一個方法
: 另一個方法是設 PYTHONIOENCODING 這個環境變數
: 參考 http://wp.me/p3U05-aC
我先照他說的 新增一個環境變數 PYTHONIOENCODING 值為UTF-8
然後執行這段程式碼:
import sys, locale, os
print(sys.stdout.encoding)
print(sys.stdout.isatty())
print(locale.getpreferredencoding())
print(sys.getfilesystemencoding())
print(os.environ["PYTHONIOENCODING"])
print(chr(246), chr(9786), chr(9787))
我的執行結果:
UTF-8
True
cp950
mbcs
UTF-8
Traceback (most recent call last):
File "a.py", line 7, in <module>
print(chr(246), chr(9786), chr(9787))
ValueError: chr() arg not in range(256)
請按任意鍵繼續 . . .
跟他的執行結果不一樣
他可以印出 chr(246), chr(9786), char(9787) 但我不行@@
(我在Windows跟Linux測 都印不出來)
--
※ 發信站: 批踢踢實業坊(ptt.cc)
◆ From: 140.112.30.46
→
04/23 13:34, , 1F
04/23 13:34, 1F
哦哦...原來他是在py3k測那段code的
查了一下 py3k的chr()相當於py2.x的unichr()
修改code如下
import sys, locale, os
print(sys.stdout.encoding)
print(sys.stdout.isatty())
print(locale.getpreferredencoding())
print(sys.getfilesystemencoding())
print(os.environ["PYTHONIOENCODING"])
print type(unichr(246))
print unichr(246)
print unichr(9786)
print unichr(9787)
print unichr(246).encode('utf8')
print unichr(9786).encode('utf8')
print unichr(9787).encode('utf8')
print unichr(246).encode('big5')
print unichr(9786).encode('big5')
print unichr(9787).encode('big5')
執行結果(under Windows):
UTF-8
True
cp950
mbcs
UTF-8
<type 'unicode'>
繹
?
?
繹
?
?
Traceback (most recent call last):
File "a.py", line 14, in <module>
print unichr(246).encode('big5')
UnicodeEncodeError: 'big5' codec can't encode character u'\xf6' in position 0: illegal multibyte sequence
請按任意鍵繼續 . . .
執行結果(under Linux)(我把印PYTHONIOENCODING那行注解了):
UTF-8
True
UTF-8
UTF-8
<type 'unicode'>
ö
☺
☻
ö
☺
☻
Traceback (most recent call last):
File "a.py", line 14, in <module>
print unichr(246).encode('big5')
UnicodeEncodeError: 'big5' codec can't encode character u'\xf6' in position 0: illegal multibyte sequence
為什麼那個人在Windows上印的出那些Unicode字元呢??
※ 編輯: Holocaust123 來自: 114.35.212.106 (04/23 14:14)
→
05/14 00:18, , 2F
05/14 00:18, 2F
→
03/30 04:38, , 3F
03/30 04:38, 3F
討論串 (同標題文章)
本文引述了以下文章的的內容:
完整討論串 (本文為第 2 之 2 篇):
Python 近期熱門文章
PTT數位生活區 即時熱門文章