[情報] 簡化平行開發 NVIDIA宣佈CUDA 4.0
NVIDIA公司今天宣佈了新版GPU通用計算開發包CUDA 4.0,主要改進方向是簡化並行編程
,讓更多開發人員能夠將應用程序移植到GPU平台。
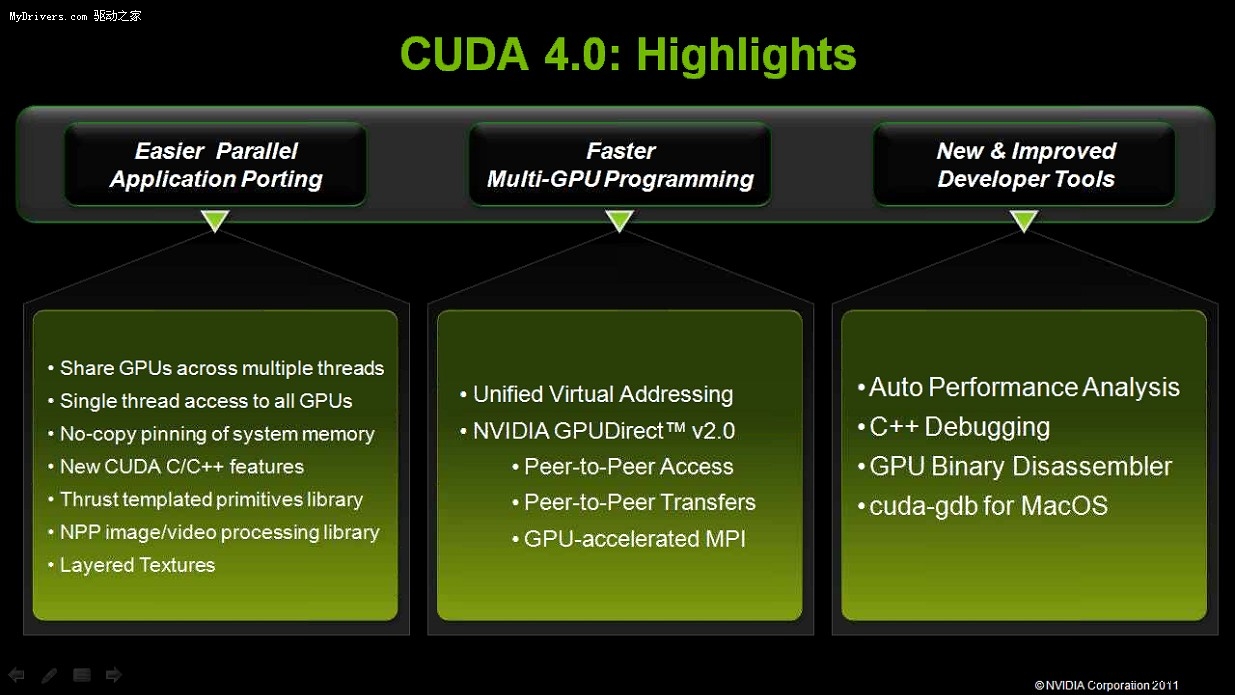
CUDA 4.0的三大主要特性包括:
http://news.mydrivers.com/Img/20110228/05541945.jpg

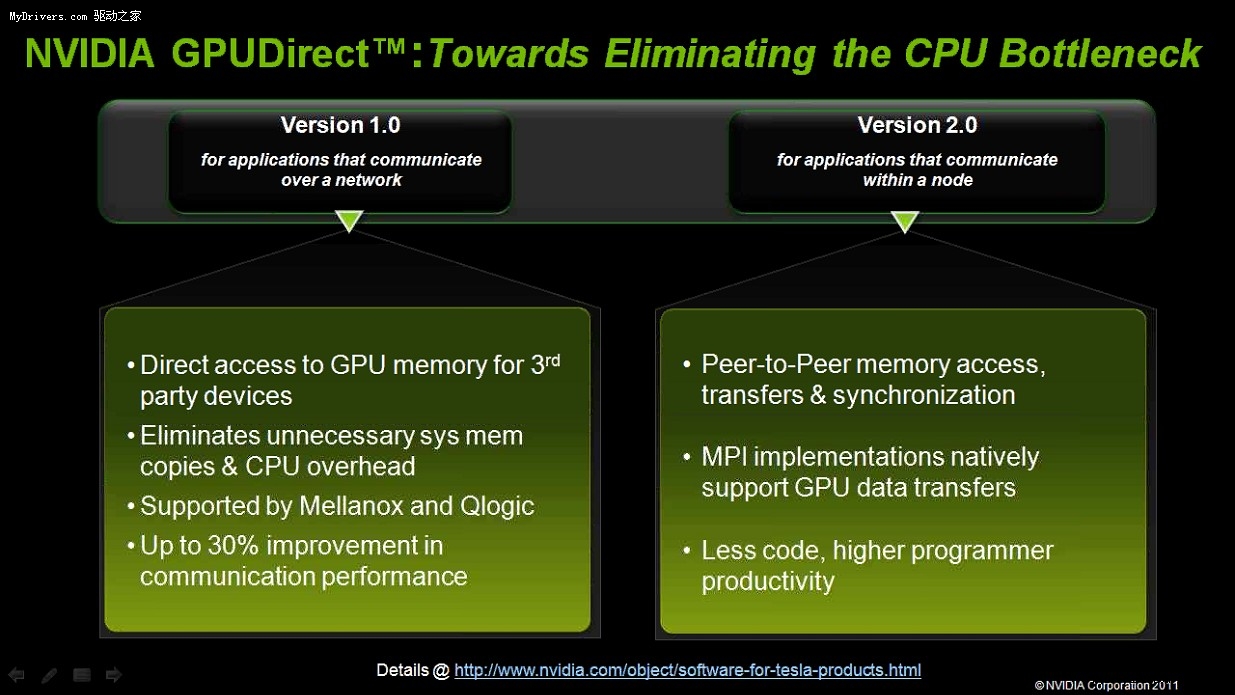
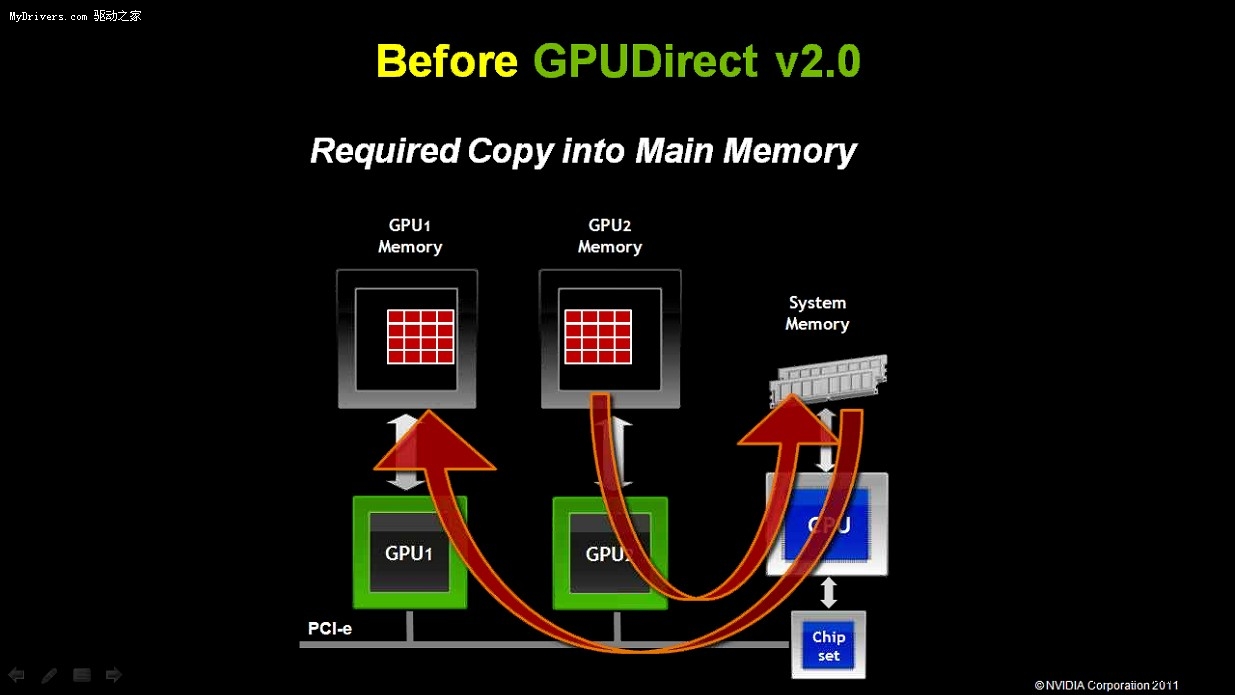
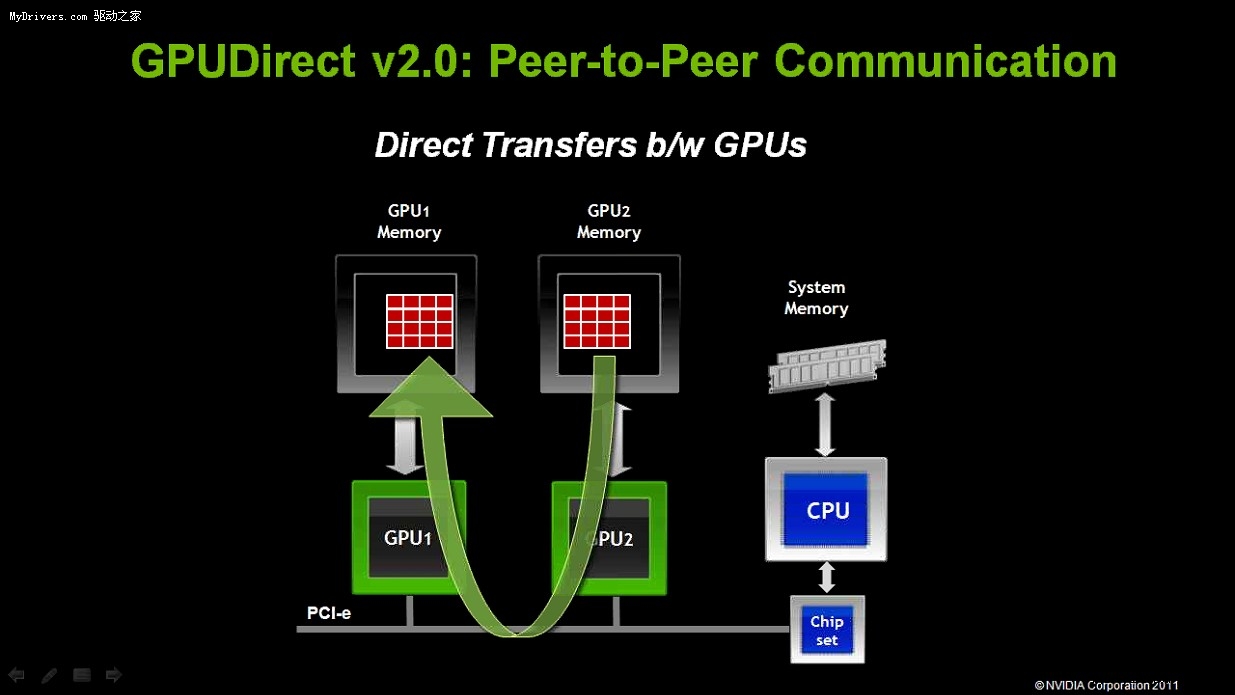
- GPUDirect 2.0技術。GPUDirect 1.0主要用於高性能計算集群應用,方便不同節點之間
的GPU相互聯繫,而GPUDirect 2.0則面向節點內應用,即多GPU並聯繫統。同一節點內的
多塊GPU可以不經過CPU、住內存,直接交換各自顯存中的數據。
http://news.mydrivers.com/Img/20110228/05544420.jpg
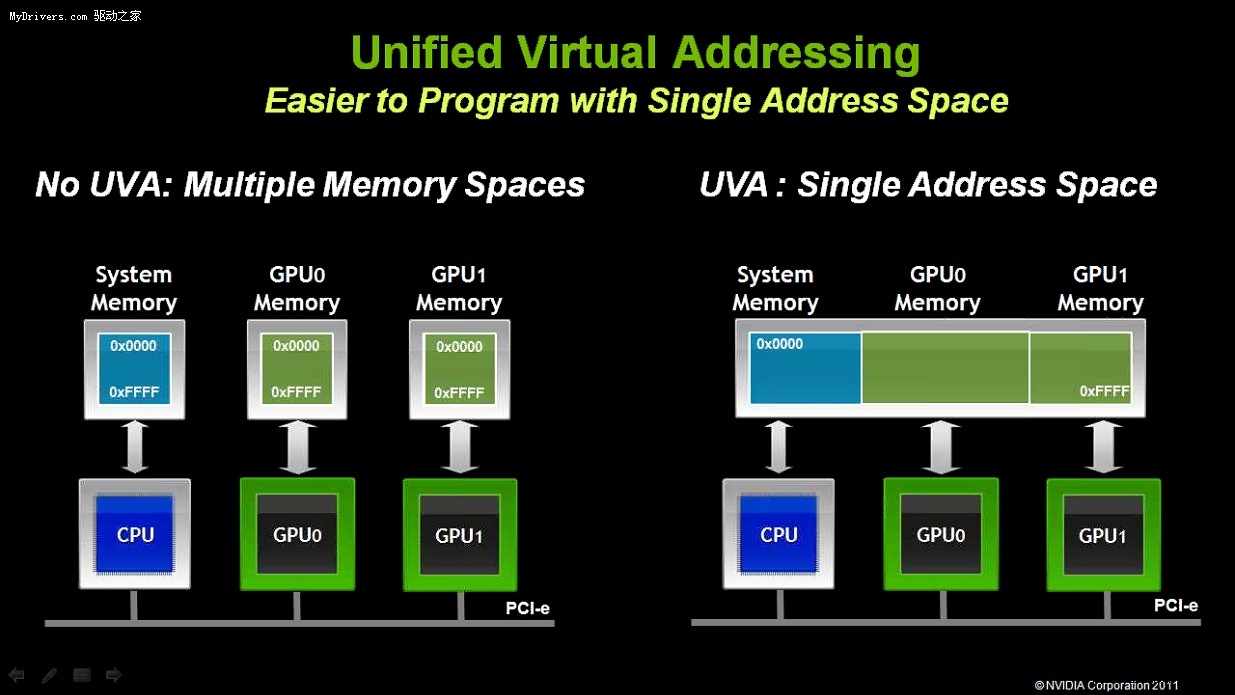
- 統一虛擬尋址(UVA)。簡化通用計算編程中的尋址空間設計,開發者不需要再考慮CPU和
各個GPU各自的內存空間,而是整合為一個統一的內存尋址空間,大大簡化並行編程。
http://news.mydrivers.com/Img/20110228/05544483.jpg
- Thrust C++模板高性能基元庫。能夠提供一系列開源C++並行算法和數據結構,這些內
容能夠讓C++開發人員更輕鬆的使用CUDA編程。與使用標準模板庫(STL)以及線程構件
(TBB)時相比,Thrust中並行排序等算法的速度可提升5至100倍。
http://news.mydrivers.com/Img/20110228/05544505.jpg

除此之外,CUDA 4.0的新特性還包括:
- MPI與CUDA應用程序相結合。當應用程序發出MPI收發調用指令時,例如OpenMPI等MPI軟
件可通過Infiniband接口自動收發顯卡顯存數據。
- GPU多線程共享。多個CPU主線程能夠在一顆GPU上共享運行環境。
- 單CPU線程共享多GPU。一個CPU主線程可以訪問系統內的所有GPU。
- 全新的NPP圖像與計算機視覺庫。
- 新增、改良的功能
Visual Profiler中的自動性能分析功能
Cuda-gdb中的新特性以及新增了對Mac OS的支持
新增了對C++特性的支持,這些特性包括新建/刪除以及虛擬等功能
新版GPU二進制反彙編程序
CUDA 4.0在硬件上需要Fermi架構GPU才能夠提供完整支持,操作系統方面則仍然支持
Windows、Mac OS X、Linux等系統。3月4日起,CUDA註冊開發者計劃會員將可以免費下載
CUDA Tool Kit 4.0 RC發佈候選版。
http://news.mydrivers.com/Img/20110228/05554900.jpg
http://www.nvidia.com/object/cuda_home_new.html
http://news.mydrivers.com/1/187/187400.htm
--
※ 發信站: 批踢踢實業坊(ptt.cc)
◆ From: 140.121.197.68
VideoCard 近期熱門文章
PTT數位生活區 即時熱門文章