[徵文] FFTNet(含實作)
小弟之前沒接觸過這類autoregressive model,可能用語會不太精確
請鞭小力點> <
Abstract
FFTNet: A Real-Time Speaker-Dependent Neural Vocoder
這是一篇發表在今年icassp 2018的paper,其提出了一個由WaveNet衍生出來的model--
FFTNet,且做了兩點改進:
1) 加快了生成速度,甚至可以realtime的生成
2) 產生的audio聽起來比WaveNet更自然
論文以及audio檔試聽:http://gfx.cs.princeton.edu/pubs/Jin_2018_FAR/index.php
I. Introduction
自從WaveNet問世後,大家發現直接用CNN合成waveform是可行的,在許多task也有不少成
功的例子(很多citations~)。但WaveNet最為人詬病的就是大量training時間以及非常慢的
生成速度。如果換成如mcc這樣的acoustic feature,則training時間可以縮短;運算時間
上也有許多加速的方法。
FFTNet使用更簡單的架構與更少的參數量,把生成的時間壓到更低,使realtime生成變為
可行(摸斗嗨雅苦~)。
II. Method
2.1 WaveNet vocoder
這裡大概講述了WaveNet的架構,基本架構是多層dilated causal CNN,其dilation隨著深
度指數成長,如下圖:
https://i.imgur.com/Dtdz5Zz.jpg

隨著層數(L)的加深,WaveNet能看到的sample數量會指數增加(2^L)。而每一層的output z
可以表示成一個gated架構
z = tanh(W_f *d x + V_f *d h) ⊙ sigmoid(W_g *d x + V_g *d h)
在這裡x代表前一層的output,W_f和W_g分別是filter和gate的convolution kernels,
V_f和V_g則是對h (auxiliary condition)做convolve的1x1 kernels。最後再對z做1x1
convolution才是final output。加上skip connections、一些conv1x1和relu後接一個so-
ftmax,去predict當前sample的256個quantized後的值。
每次forward只能生出一個sample,速度hen慢,即使是加了cache的Fast WaveNet,每秒也
只能生200個samples。
2.2 FFTNet architecture
從WaveNet的圖可以發現,和預測的sample相關的node連起來就像是個二元樹,讓人聯想
到經典的演算法--FFT。FFT使用了divide and conquer的概念,將input分成更小段的子
input去做DFT。
N-1
令Σ x_n*e^(-2*pi*i*n*k/N) = f(n, N)
n=0
則f(n, N)可拆解成
f(2n, N/2) + f(2n+1, N/2)
=f(4n, N/4) + f(4n+1, N/4) + f(4n+2, N/4) + f(4n+3, N/4)
=...
如果我們將轉換function f 換成 1x1 convolution,則會得出一個類似FFT的模型。
http://gfx.cs.princeton.edu/pubs/Jin_2018_FAR/fftnet.png
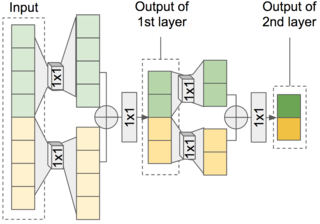
也就是將輸入的訊號分成左右兩邊,各自做1x1 convolution再相加。
z = W_L * x[:N/2] + W_R * x[N/2:]
而gated的部分就用簡單的relu代替,所以下一層layer的input
x = Relu(conv1x1(Relu(z)))
如果加上auxiliary condition,則
z = ... + (V_L * h[:N/2] + V_R * h[N/2:])
V_L和V_R也都是1x1 kernel。
※如果h不會隨時間變化,則可以用一個weight V * h 取代。
將FFTNet當vocoder使用的時候,h就是f0和MCC。要生成當前時間t的sample x[t],FFTNet
的輸入為之前生的N個sample x[t-N:t] (N = 2^L, L為model深度) 和往前一個step的fea-
ture h[t-N+1:t+1]。
最後接一個大小256的fully connected和softmax就完成惹。
2.3 Training Techniques
這邊提了幾個訓練FFTNet和生成samples時需要的技巧。
2.3.1 Zero padding
訓練時每段samples的前面多pad N個zeros。如果沒加zero padding,model在生成時容易
有雜音,或是input非常微弱時會卡住。
2.3.2 Conditional sampling
選擇softmax的output通常有兩種方式,一種是argmax一種是random sampling from post-
terior。argmax可以選擇出最小training error的答案,但是我們希望model的輸出也有原
訓練資料本身自然的noise distribution,例如沒有人聲時的waveform。於是採用random
sampling,並在有人聲的部分於softmax前多乘上一個常數c,使distribution比較sharp;
沒人聲的部分就是原本的distribution。實驗時c=2。
2.3.3 Injected noise
因為training error,model的output都會有一些noise,而生成的這些output都會餵回去
當作下個sample的input,於是noise越來越大,最後生出來的音檔就會有啪嚓聲。在訓練
時加入noise可以加強model的穩定性。實驗時觀察到model的prediction常常只差上下一個
class,所以訓練加的noise為平均值0,標準差1/256的高斯分布。
2.3.4 Post-synthesis denoising
由於前一階段injected noise使model產出的sample在人聲部分都有一點noise,於是作者
使用spectral subtraction noise reduction 當作post processing。這好像是高等DSP
才會教的東西,我也沒有細看> <
3. Evaluation
作者用CMU Arctic dataset來訓練model,詳細的實驗設定與細節就不多說惹。
總共比較了五種model:
1. MLSA filter (baseline)
2. WaveNet + zero-padding
3. FFTNet + zero-padding
4. WaveNet + all 2.3 techniques
5. FFTNet + all 2.3 techniques
實驗時WaveNet和FFTNet的receptive field都一樣(2048 samples)。
在主觀測試中,加了所有2.3部分的FFTNet表現比原本好上許多,並且和WaveNet不相上下
,代表這些小撇步對FFTNet是需要的;而分數也顯示2.3的techniques一樣能improve Wav-
eNet的表現。
而作者也提到FFTNet在一顆i7的cpu上,只要0.81秒就能生出一秒長度的音檔Σ(;゚д゚)
4. Conclusion
提出了一個簡單且能快速生成audio的架構,並結合一套訓練與post processing的技巧,
使這樣簡單的Model在當成vocoder時,能產生出state of the art的結果;而這些技巧也
能改善WaveNet的結果。
----
個人心得:
心得不知道要寫甚麼,就來寫點我對FFTNet的理解,還有一些疑問與實作上的問題ㄅ
在FFTNet架構的部分,如果把兩個1x1的kernel結合,形成一個大小1x2,dilation=N/2的
kernel,則架構圖可以重新表示成
https://i.imgur.com/NWfSTpz.png

如果將所有的node畫出來
https://i.imgur.com/Vsotxec.png

再從反方向走回去
https://i.imgur.com/rAINJYk.png

就得到一個上下顛倒的WaveNet架構。
換言之,FFTNet是WaveNet的transpose,而且拿掉gated和skip connections。如果真是這
樣,我覺得作者其實應該要放一個原本Wavenet dilated架構,但全部只有convolution和
relu的模型來比較。而且這樣來說兩個的complexity應該相去不遠,那為甚麼FFTNet可以
做到real-time?實作時我生成的速度大約是每秒300個samples(有cache),跟WaveNet比雖
然快,但完全沒有到realtime的程度。而github上我看其他人也差不多是這個速度。
這是我目前最大的疑問qq
魯魯有自己implement FFTNet放在github,還在施工中,不過目前生出來的sample大概跟
作者網站上原始的FFTNet差不多,也歡迎大家來逛逛我的repo~
https://github.com/yoyololicon/pytorch_FFTNet
--
※ 發信站: 批踢踢實業坊(ptt.cc), 來自: 111.241.48.227
※ 文章網址: https://www.ptt.cc/bbs/DataScience/M.1534082114.A.474.html
推
08/14 00:50,
8年前
, 1F
08/14 00:50, 1F
→
08/14 06:45,
8年前
, 2F
08/14 06:45, 2F
推
08/18 16:36,
8年前
, 3F
08/18 16:36, 3F
→
08/19 09:37,
8年前
, 4F
08/19 09:37, 4F
DataScience 近期熱門文章
PTT數位生活區 即時熱門文章